在这几天中,我拿出了若干个小时来编写爬虫和其他分析程序,来慢慢填补之前挖下的一个天坑。
在取得了初步的进展之后,我进行了第一阶段的总结。
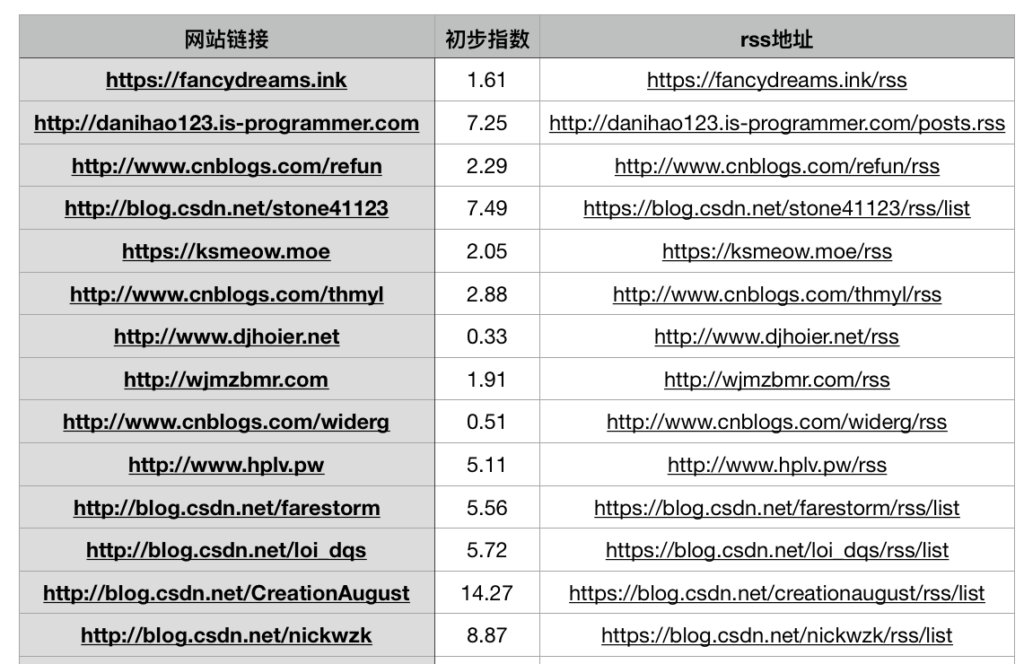
项目的目的是要爬取OIer们的博客,并最终了解信息学竞赛选手之间联系。同时,我认为完成之后也可以分析词出现的频率,分析出一些正在发生的变化,或者制作一个博客集合,将最新的博文爬下来。
在这几天中,我大概干了如下的事情
- 编写程序自动从博客首页获取博客RSS地址,并(如果可能)基于博客RSS爬取博客标题
- 使用Github上的汉语分词工具,以洛谷上的算法标签和其他竞赛词汇作为自定义词库辅助将博客标题分词
- 通过统计词频给出一个博客可能是信息学竞赛选手博客的指数
- 使用上述工具编写初步爬虫,并爬取了200个博客,根据两百博客中4357个博客标题再次进行分析,生成了更精确的词频
-1-252x300.png)
使用了RSS作为分析的工具,解决了csdn,cnblogs等最多数OI选手选用的博客和大量自建博客。但与此同时,如洛谷博客,部分选手的自建博客仍然没能解决。
在下一阶段中,我将会
- 改进程序以识别不支持RSS的信息学竞赛选手博客
- 减少不必要的请求数量,提高程序效率
- 爬取能爬取的全部信息学竞赛选手,并分析博客之间的链接关系
希望在一周之内完成以上内容之后,我还希望在两周之内完成
- 从主流信息学竞赛OJ和网站中爬取(公开的)用户信息,从而了解一些信息学竞赛选手在该OJ上账号与对应博客的关联关系
- 通过链接文字推测博客和id的联系,并最终同信息学竞赛数据库融为一体。
之前不论是在干什么,过一段时间总可能会咕掉,于是我就把这个写在博客上,以便于能够让自己坚持下去。
发表回复